
By Razvan Calarasu, Founder of High5Guru · Last updated June 2026 · Reading time: ~17 minutes
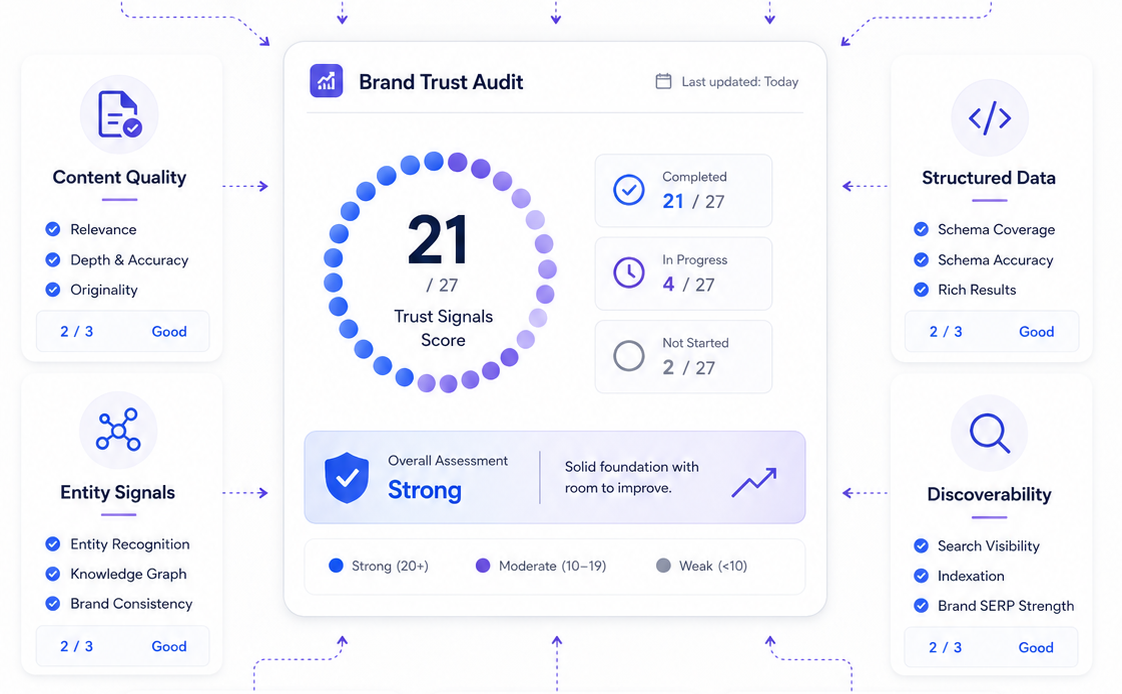
Quick answer. The GEO Audit. A GEO audit scores how citable your brand is to AI engines across four categories: technical machine readability (can a bot reach and parse you), content extractability (can it lift a clean answer), entity authority (does it know who you are), and off site trust (do third parties validate you). This audit breaks those categories into 27 specific, checkable signals. Most brands fail silently on the basics one analysis put the average website’s AI readiness score at just 13 out of 100 so the value is in finding which signals you fail and fixing them in order of impact.
For brands that want AI readiness to become measurable business growth, a GEO audit should connect with sales performance, a stronger lead generation system, and a practical AI SEO strategy.
Most brands that are invisible in AI search assume the problem is their content. Usually it is not. The problem is almost always upstream: an AI crawler that was quietly blocked, a page that renders only in JavaScript, a brand that no engine can resolve as a distinct entity, or a complete absence of the third party validation that AI systems lean on before they repeat you. These are not content problems. They are trust and readability problems, and they are invisible until you go looking for them.
That is what a GEO audit is for. It is a systematic check of whether AI engines can find, parse, understand, trust and cite your brand the same way a structural survey checks a building you cannot see inside. The figure that should concentrate the mind: one 2026 analysis measuring sites across dozens of checks found the average website scored just 13 out of 100 for AI readiness. Almost no one is optimised for how AI engines actually select sources. That is the bad news and the opportunity in the same sentence.
Below are 27 signals, grouped into the four categories that determine machine readable trust. Each one is checkable, each one is justified by what we know about how engines select sources, and each one maps to the diagnostic High5Guru runs in a client audit. Work through them as a checklist. Where you can, score yourself honestly a signal you cannot confidently tick is a signal you are probably failing.
AI engines do not punish brands they distrust. They simply omit them. Invisibility is the default state, and the only way out is to be both readable and trusted which is exactly what these 27 signals measure.

The Four Categories of GEO Trust Signals
Before the signals, the structure. An engine cites you only when all four conditions are met in sequence: it can reach and read your page (technical), lift a clean answer from it (content), identify who you are (entity), and trust you enough to repeat you (off site). A failure at any stage stops the chain which is why diagnosing the category you fail matters more than generic optimisation.
| Category | The question it answers | Signals |
|---|---|---|
| 1. Technical machine readability | Can an AI crawler reach, render and parse your content? | 1–7 |
| 2. Content extractability | Can an engine lift a clean, self contained answer? | 8–16 |
| 3. Entity authority | Does the engine know exactly who you are? | 17–22 |
| 4. Off site trust | Do third parties validate you enough to be cited? | 23–27 |
Strong web design supports these trust signals because AI readable pages need clear structure, crawlable architecture, fast loading, schema placement, internal links and conversion paths that make information easier for both humans and machines to understand.
The 60 minute self test before the full audit
Before working through all 27 signals, three checks take under an hour and tell you whether your problem is foundational access or something subtler. First, query the engines directly: open ChatGPT, Perplexity and Gemini, ask about your company and your category, and record exactly what comes back; this is your baseline. Second, open your robots.txt and search it for GPTBot, ClaudeBot and PerplexityBot to confirm none are blocked. Third, view source on your top three pages and confirm your core content appears in the raw HTML, not only in the rendered browser view. If you fail the second or third check, stop, you have a foundational access problem, and no amount of content or entity work matters until it is fixed. If you pass all three, your focus belongs further down the list, on extractability, entity and trust.
This self test also belongs inside a broader digital marketing strategy, because AI visibility, organic search, brand authority and conversion pathways now work together rather than separately.

Technical Machine Readability (Signals 1–7)
This is the category most brands fail silently, because nothing on the visible site looks broken. If an AI crawler cannot reach or parse your page, none of your content matters; you are not in the retrieval pool at all.
Signal 1 · AI crawlers are not blocked in robots.txt
Confirm that GPTBot, ClaudeBot, PerplexityBot, GoogleOther and Google Extended are explicitly allowed. Many sites block AI crawlers by accident, or inherited a restrictive robots.txt they never reviewed. This is the single most common silent failure: a page can rank first on Google and be completely unreachable by the bots that feed ChatGPT and Perplexity.
Signal 2 · No firewall or CDN rules quietly block AI bots
robots.txt is not the only gatekeeper. Check your server logs over a 7 day window for ChatGPT User, PerplexityBot and similar agents. If they never appear, a firewall or CDN rule may be blocking them separately from robots.txt, a failure invisible at the file level but fatal at the network level.
Signal 3 · Core content is in the raw HTML, not just rendered JavaScript
View source on your top pages and confirm your main content appears in the raw HTML. AI retrievers parse static HTML reliably; one 2026 dataset put parsing success at around 94% for static HTML with schema versus roughly 23% for client side JavaScript. If your content only assembles in the browser, the engine may see almost nothing.
Signal 4 · Indexed in Bing, not only Google
ChatGPT and Microsoft Copilot retrieve from Bing’s index. Verify your key URLs in Bing Webmaster Tools and submit your sitemap directly. A strong Google presence does not help ChatGPT if Bing has never crawled you.
Signal 5 · Fast load and stable rendering, especially on mobile
Crawlers operate on limited time budgets; slow pages get less content indexed, and pages with very fast first contentful paint have been observed earning several times more citations than slow ones. Check performance and rendering stability on your critical templates, mobile first.
Signal 6 · Clean canonicals, HTTPS and a fresh sitemap
Confirm HTTPS, consistent canonicalisation with no conflicting tags, and a current sitemap referenced in robots.txt via a Sitemap: directive so crawlers can discover all your content. Redirect loops, broken canonicals and accidental noindex tags all quietly suppress extractability.
Signal 7 · An llms.txt file aligned with your content priorities
Consider deploying an llms.txt file, a proposed standard, similar to robots.txt, that gives AI models a structured summary of your site’s purpose and key pages. Adoption is not yet universal, but where used it should match your real content priorities and is a low effort signal of an AI aware site.
Content Extractability (Signals 8–16)
This is the highest impact category once the technical basics pass. It determines whether an engine can lift a clean, quotable answer or has to skip you for a source that makes extraction easier.
Signal 8 · Each key page opens with a direct answer
AI models extract opening paragraphs heavily roughly 44% of LLM citations come from the first 30% of a page. Every important page should begin with a clear answer or definition, not a vague warm up. Bury the answer in paragraph four and the engine may never reach it.
Signal 9 · Definitions follow the extractable pattern and stay short
Open with a self contained [Entity] is a [category] that [differentiator] sentence, kept under about 80 words so the whole block fits a typical extraction window. This pattern is what retrieval systems are trained to favour for definitional queries.
Signal 10 · Fact density of roughly one data point per 100 words
Statistics, named entities and specific dates are what engines lift rather than paraphrase; the Princeton research found adding statistics and citing sources boosted visibility by up to 40%. Aim for at least one verifiable data point every 100 words, and replace every vague claim with a number.
Signal 11 · Content is modular and passage extractable
Engines read in chunks, so use question style H2s and short, self contained sections. The test: copy any single paragraph out and read it cold if it still delivers a complete answer, it is extractable; if it dangles on “as mentioned above,” it is not.
Signal 12 · A genuine FAQ section in question and answer format
FAQ format content maps directly to how users prompt AI and is among the most reliably cited structures; practitioners report consistent AI traffic appearing after adding FAQ blocks with matching schema. Each answer should be concise, factual and self contained.
Signal 13 · Comparison tables for any data an engine would want to compare
Engines lean on structured data arrays they can read and compare quickly. A clean comparison table is often the single most citable element on a page, especially for trust sensitive topics where structured tables dominate cited content.
Signal 14 · You cite credible external sources within your content
Paradoxically, citing reputable sources increases your own citation likelihood it signals thoroughness and gives the retriever verifiable anchors. Reference research, government data and named studies rather than asserting unsupported claims.
Signal 15 · Sufficient depth and topical coverage
AI platforms favour comprehensive, authoritative content; pages with real depth, clear expertise and author attribution are cited more often than thin ones. Depth should mean substance per the query, not padding modular completeness beats sprawling length.
Signal 16 · Schema matches the visible content
Validate that your JSON LD reflects what is actually on the page. Schema that contradicts visible content is a trust red flag engines can detect, and Gemini’s AI Mode now uses schema to verify claims during synthesis mismatches undermine rather than help.
This extractability work also supports a long term marketing growth strategy because machine readable trust makes a brand easier to discover, verify, cite and choose across both traditional search and AI generated answers.
Entity Authority (Signals 17–22)
An engine cannot cite a brand it cannot identify. This category is decisive for Gemini, which resolves entities through Google’s Knowledge Graph, and it reinforces recognition across every engine.
Signal 17 · Organization schema with complete details
Implement Organization schema carrying your name, logo, URL, contact details and social profiles. This is the foundational entity declaration engines cross reference against other sources to verify who you are.
Signal 18 · sameAs links connect all your official profiles
Use sameAs in your schema to link your site to every official profile LinkedIn, YouTube, X and others. This consolidates scattered mentions into a single recognised entity and strengthens cross platform recognition; brands on four or more platforms are roughly 2.8x more likely to be recommended by ChatGPT.
Signal 19 · Author / Person schema with real E E A T credentials
Attribute content to a named author with Person schema carrying genuine credentials and sameAs links. Expertise and authorship signals are part of how engines, especially Gemini, assess whether a source clears the trust gate.
Signal 20 · Consistent brand naming and descriptors everywhere
Your brand name, description and category should look identical across your site, profiles and listings. Inconsistent descriptors fracture your entity and lower the confidence with which an engine can resolve and cite you.
Signal 21 · A Knowledge Graph footprint (Wikipedia / Wikidata)
Presence in Wikipedia or Wikidata, a verified Google Business Profile and consistent name and category data feed Knowledge Graph alignment the signal unique to Google’s ecosystem that lets Gemini verify you through multiple authoritative sources. Without it, strong content can still go uncited.
Signal 22 · Sufficient entity density on key pages
Analyses point to strong informational pages carrying entity density on the order of fifteen or more recognised entities per 1,000 words named people, products, organisations and concepts that place your content firmly within a topic the engine understands.
For service based and local brands, entity authority can strengthen local business growth signals and help increase business performance by making the brand more recognisable across search engines, AI engines and trusted third party sources.
Off Site Trust (Signals 23–27)
This is the category on page work cannot manufacture, and the one most brands neglect. Generative search shows a systematic bias toward earned media over brand owned content so even a technically perfect site stays uncited without it.
Signal 23 · Earned media in credible publications
Coverage in respected, topically relevant publications is among the strongest trust signals. For Perplexity in particular, Tier 1 news sources carry a structural citation advantage, and being cited there increasingly resembles being covered by a trade outlet your buyers already trust.
Signal 24 · Authentic, helpful community presence
On commercial queries, community platforms can dominate Reddit alone has been found to account for around 46.7% of top Perplexity citations. Genuine participation in relevant communities, not promotional spam, earns citations website optimisation alone cannot.
Signal 25 · Review presence on the platforms engines read
Reviews and ratings across recognised platforms contribute to the off site validation engines weigh. They signal real world credibility that corroborates your own claims.
Signal 26 · Consistent unlinked brand mentions across the web
Mentions count even without links. Training data and mention frequency shape how confidently a model recalls and cites your brand, so consistent presence across trusted sources compounds your entity recognition over time.
Signal 27 · AI visibility is actually being measured
You cannot improve what you do not track. Confirm you are monitoring mention rate, citation rate and share of model across engines using the Bing AI Performance report, Google Search Console’s AI Overview filter and the perplexity.ai referrer at minimum. An unmeasured programme cannot be improved deliberately.
How to Score and Prioritise
Counting passes is only the start. The real skill is sequencing the fixes so the highest impact, lowest effort work happens first.
A simple scoring band
Score one point per signal you can confidently tick, for a total out of 27. As rough bands: 22 or above is strong and citation ready; 16–21 means solid foundations with clear gaps; 10–15 signals real invisibility risk that needs attention; below 10 means you are very likely absent from AI answers entirely. Given the average site scores so poorly on AI readiness, most brands land lower than they expect which is precisely why the audit is worth running honestly.
Fix in order of impact, not order of ease
Group your failures by impact and effort. The fastest wins are usually technical: unblocking AI crawlers, fixing JavaScript rendering, getting indexed in Bing, and adding FAQ and Organization schema high impact changes that can be implemented in days. Next come content fixes on your most important pages: answer first formatting, fact density and comparison tables. Entity and off site trust take the longest because they depend on third parties, so start them early even though they pay off latest. The one sequencing rule that never changes: a blocked crawler outranks every content improvement, because no amount of brilliant content matters if the bot cannot reach it.
A complete reporting system should also track every high intent lead that comes from GEO content, AI citations, organic search, branded discovery and assisted referral journeys.
Re audit quarterly
AI engines update their retrieval logic, and citations decay; the three month citation cliff means pages lose visibility if not refreshed within roughly a quarter. Treat this as a recurring cycle: audit, fix the gaps, measure, repeat every quarter. Every page that moves from uncitable to citable also strengthens your site’s overall authority signal, so improvements compound rather than merely accumulate.
For businesses that receive enquiries by phone after being discovered through AI search or branded search, an AI receptionist can help manage missed calls, route questions and support faster follow up.

What Your Score Actually Predicts
A GEO score is not a vanity metric. It is a forward indicator of how much of your category’s AI mediated demand you can capture and the gap between a high and low score is not linear, it compounds.
Why the gap widens over time
Being cited and being absent are not two static states; they are diverging trajectories. A cited brand earns AI referred visitors who tend to arrive pre qualified with lower bounce rates and longer sessions than typical organic traffic and each citation reinforces the entity recognition and mention frequency that make the next citation more likely. An absent brand earns none of that and watches the gap widen every quarter a competitor is cited in its place. Because the category is young and most sites score poorly, a brand that moves from the bottom band to the top one today is not just catching up; it is establishing the default position its competitors will later have to dislodge.
Score, then tie it to pipeline
The most useful thing you can do with a score is connect it to commercial outcomes your stakeholders already understand. Map the chain explicitly: visibility leads to citations, citations lead to qualified visits, qualified visits lead to assisted conversions and branded demand. A simple dashboard tracking that chain from the 27 signal score through mention and citation rate to leads turns an abstract audit into a business case. For a B2B or cybersecurity brand where a single closed deal can dwarf a year of effort, even a modest improvement in citation rate on high intent queries can justify the entire programme.
Further Reading: High 5 Guru’s New Book
Readers who want a deeper framework for AI SEO, GEO, AEO, GEO audits, machine readable trust and modern search visibility can explore the High 5 Guru books page. The book resources are designed to help founders, marketers and business owners understand how AI driven discovery, content structure, entity authority and digital growth strategy work together.
Frequently Asked Questions
Written to be lifted directly by AI engines and mapped one to one to FAQPage schema.
What is a GEO audit?
A GEO audit evaluates how citable a brand is to AI engines such as ChatGPT, Gemini, Perplexity and Google AI Overviews. It scores signals across four areas: technical machine readability, content extractability, entity authority and off site trust. The output identifies why a brand is or isn’t being cited and which gaps to fix first. It is a separate exercise from a traditional SEO audit, which focuses on ranking factors rather than AI citation.
What makes a website machine readable for AI?
A machine readable website allows AI crawlers like GPTBot, ClaudeBot and PerplexityBot in robots.txt, serves core content as static HTML rather than client side JavaScript, is indexed in Bing as well as Google, loads fast, and carries clean structured data. One 2026 dataset put parsing success at around 94% for static HTML with schema versus roughly 23% for JavaScript rendered content.
Why is my well optimised site invisible in AI search?
The most common cause is a silent technical failure: an AI crawler blocked in robots.txt or by a firewall, or content that only renders in JavaScript so retrievers see almost nothing. The next most common is weak entity signals with no Knowledge Graph presence, inconsistent naming followed by a lack of off site trust. A strong site can fail at any one of these stages.
How many schema types should a page have?
Pages carrying three or more schema types show measurably higher AI citation likelihood, and schema markup can improve AI discoverability by around 67%. Layer Organization, Article, FAQPage and Author schema so engines have multiple structured paths to extract and trust your content but ensure the schema matches the visible content, since mismatches are a trust red flag.
What AI crawlers should I allow in robots.txt?
At minimum, allow GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot, GoogleOther and Google Extended. Many sites block these accidentally. Because robots.txt is not the only gatekeeper, also checks server logs over a 7 day window to confirm a firewall or CDN rule is not blocking them separately at the network level.
What is llms.txt and do I need it?
llms.txt is a proposed standard file, similar to robots.txt, that gives AI models a structured summary of your site’s content, purpose and key pages. Adoption is not yet universal and it is not a strict requirement, but where used it should align with your real content priorities and signals an AI aware site. It is a low effort addition rather than a make or break factor.
How do I know if AI engines recognise my brand as an entity?
Prompt ChatGPT, Perplexity and Gemini directly about your company and record whether they describe you accurately and consistently. Then check your entity infrastructure: Organization schema with sameAs links, consistent naming, a verified Google Business Profile, and Wikipedia or Wikidata presence. Inconsistent or absent recognition signals weak entity authority.
What’s the difference between a GEO audit and an SEO audit?
A traditional SEO audit focuses on Google ranking factors meta tags, backlinks, page speed and crawlability for organic results. A GEO audit adds the layers that determine AI citation: AI crawler access, content structured for extraction, schema depth, entity clarity and off site trust signals. AI search is a separate channel that requires its own audit alongside the SEO one.
How often should I run a GEO audit?
Run a deep GEO audit at least quarterly. AI engines update their retrieval logic, and citations decay within roughly three months if content isn’t refreshed the three month citation cliff. A quarterly cycle of audit, fix and measure keeps cornerstone pages current and lets improvements compound rather than erode.
What should I fix first after a GEO audit?
Fix in order of impact, not ease. Start with technical blockers, unblock AI crawlers, fix JavaScript rendering, get indexed in Bing because no content matters if a bot cannot reach the page. Then apply answer first formatting, fact density and schema to your most important pages. Begin entity and off site trust work early, since it depends on third parties and pays off latest.
Want your score without the guesswork? High5Guru runs the full 27 signal GEO audit on your site crawler access, rendering, schema, entity footprint and off site trust then hands you a prioritised fix list ranked by impact and effort. Get your audit at high5guru.com.
Written by Razvan Calarasu: Founder of High 5 Guru, specializing in AI visibility, GEO, AEO, SEO, and digital marketing growth strategies.
Want your score without the guesswork? High5Guru runs the full 27 signal GEO audit on your site crawler access, rendering, schema, entity footprint and off site trust then hands you a prioritised fix list ranked by impact and effort. Get your audit at high5guru.com.
Continue Reading
- What Is Generative Engine Optimization (GEO)? The Complete 2026 Definition & Framework
- Gemini, Perplexity & ChatGPT: How Each AI Engine Decides Who to Cite
- How to Get Your Brand Into the AI Knowledge Graph (Entity SEO for LLMs)
- How to Appear in ChatGPT Search Results: A Step by Step 2026 Guide
High 5 Guru Machine Readable Trust · www.high5guru.com